
[Tuto] VisualWget: interface pour wget sous Windows
Salut à tous ! Ce dimanche, je vais vous présenter rapidement un petit soft bien sympa que je garde dans ma trousse à outils windowsienne, VisualWget. Les linuxiens d'entre vous connaissent déjà wget, qui est un un client HTTP, HTTPS et FTP en ligne de commande qui permet de récupérer du contenu d’un serveur Web ou FTP. Il est particulièrement recommandé quand on souhaite télécharger un répertoire ou un site entier automatiquement, sans cliquer sur les liens ou les fichiers un par un. Aujourd'hui, je vous présente la version adaptée à Windows et utilisable avec une interface graphique, donc facile à prendre en main.
Pour la petite histoire, j'en suis venu à parler de cet outil car il m'a pris de vouloir télécharger l'entier des pdfs du dernier Pas Sage en Seine, car le .torrent ne contient que les .webm. Il n'y en a que 14 me direz-vous, mais comme je suis - comme tout bon informaticien - un flemmard, j'use et abuse de scripts et autres tâches automatisées dès que je le peux. Aussi, quand il y en aura 500, vous serez contents de savoir comment vous y prendre!
Le soft n'est plus trop maintenu à jour, au point que le site du développeur n'est plus accessible alors je vous le mets à disposition: VisualWget. Pour ce mini-tuto, je vais me concentrer sur un besoin précis. Je compte sur vous pour explorer toutes les options dispos !
Voici donc l'interface de l'outil:
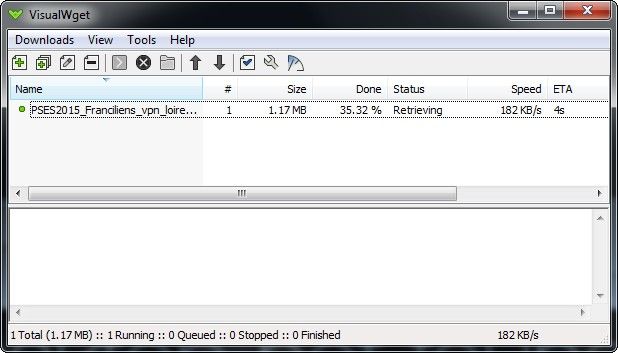
Pour ajouter un ou des liens, appuyer sur le [+] en haut. L'outil surveille le presse-papiers, le dernier lien copié est collé automatiquement. Choisissez où vous souhaitez enregistrer les fichiers:
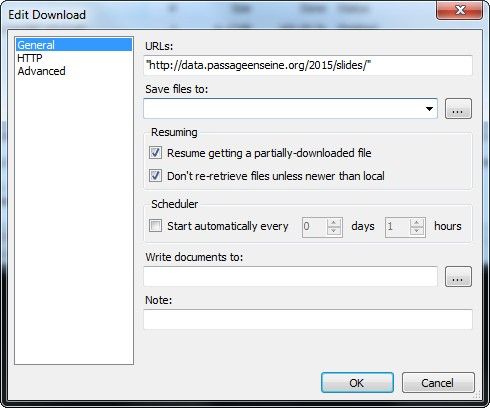
Dans notre cas, l'onglet "HTTP" ne nous intéresse pas. Passons directement à "Advanced", "Recusive Retrieval" et cochons l'option "--recursive" pour télécharger tous les fichiers et répertoires en dessous de la cible.
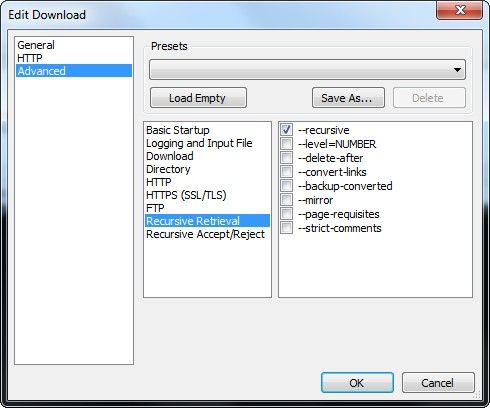
Dans "Recursive Accept/Reject", cochez l'option "--reject-LIST" et tapez "index.html*" pour éviter de télécharger tous les fichiers commençant par "index.html" suivis de n'importe quoi ("*" ayant le rôle de joker).
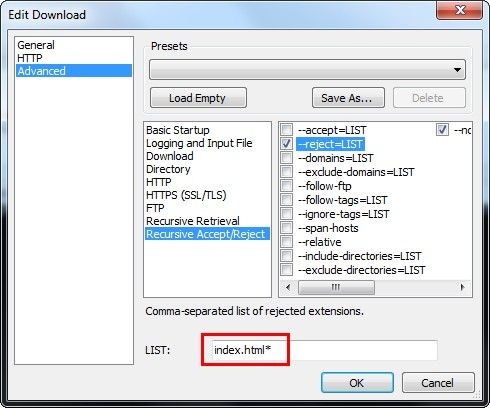
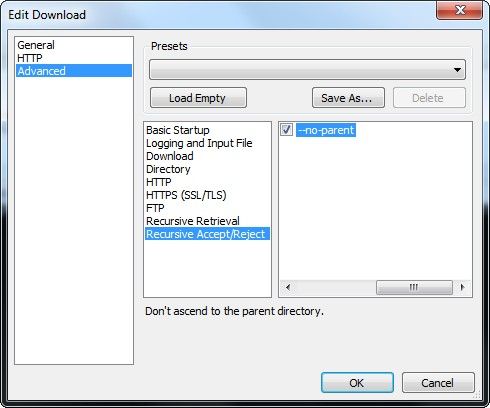
Cochez l'option "--no-parent" pour que wget ne remonte par l'arborescence et reste au niveau du répertoire "slides" qui nous intéresse ici:
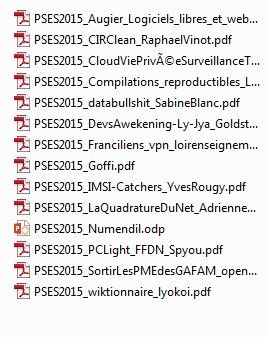
Après quelques minutes de téléchargement, vous devriez vous retrouver avec les 14 pdfs dans le répertoire que vous avez spécifié:
Si vous avez une machine sous Linux à disposition, vous pouvez y lancer wget avec les mêmes arguments, ce qui devrait conduire logiquement au même résultat. Enjoy !